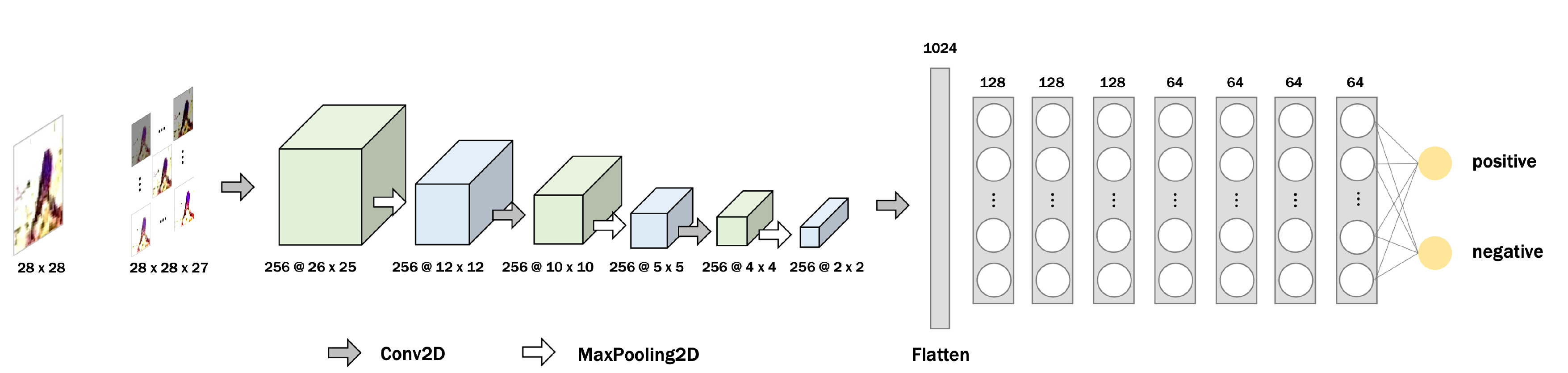
Fig. 2. A block diagram of the proposed CNN model architecture. Brightness and contrast adjustments were applied to input images for data augmentation. The proposed model comprises three convolutional (Conv2D) and three max pooling (MaxPooling2D) layers, a flatten layer, and eight dense layers. Numbers below the cubes indicate the output shape of each layer. Numbers above the grey boxes indicate the number of nodes of each flatten and dense layer. Each white circle corresponds to a single node.
© Exp Neurobiol
{kind=link}